大模型推理 - GPTQ 落地与优化
Contents
回顾前一篇文章,GPTQ给大模型带来了降本的可能,但存在性能不佳的问题,无法直接落地。经过迁移适配,我们将GPTQ的INT4 Kernel集成进FasterTransformer(简称FT),优化后可以在2卡A100运行175B的模型,对比fp16相同算力下性能提升近4倍。
看一下数据:
| 模型版本 | 模型大小 | 初始显存 | 峰值显存 | 显卡(A100)数 | 算力 | 每秒生成token数 |
|---|---|---|---|---|---|---|
| FP16 | 329G | 49G*8 | 无数据 | 8卡 | 99% | 23 |
| INT8 | 329G | 49G*4 | 50G*4 | 4卡 | 99% | 27 |
| INT4-old-cuda | 93G | 52G*2 | 54G*2 | 2卡 | 99% | 10 |
| INT4-fastest-inference-4bit | 93G | 52G*2 | 54G*2 | 2卡 | 99% | 12 |
| INT4-优化版本 | 93G | 52G*2 | 54G*2 | 2卡 | 99% | 22 |
测试基于FasterTransformer, 基础模型为bloom 175B, 模型版本:
- FP16 - 默认的推理方式,配置8卡Tensor并行,Linear算子调用的cublas的gemm
- INT8 - Weight Only量化,算子基于cutlass::gemm::kernel::GemmFpAIntB
- INT4-old-cuda GPTQ最初的开源实现,VecQuant4MatMulKernel是INT4的矩阵乘算子
- INT4-fastest-inference-4bit GPTQ-for-LLaMa项目对INT4算子做了优化,主要的改动是2个half变成一个half2
- INT4-优化版本 我们基于fastest-inference-4bit版本做了一些优化
一、FT改造
改造FT以支持GPTQ的INT4比较简单,首先了解下int4的权重文件。
权重矩阵
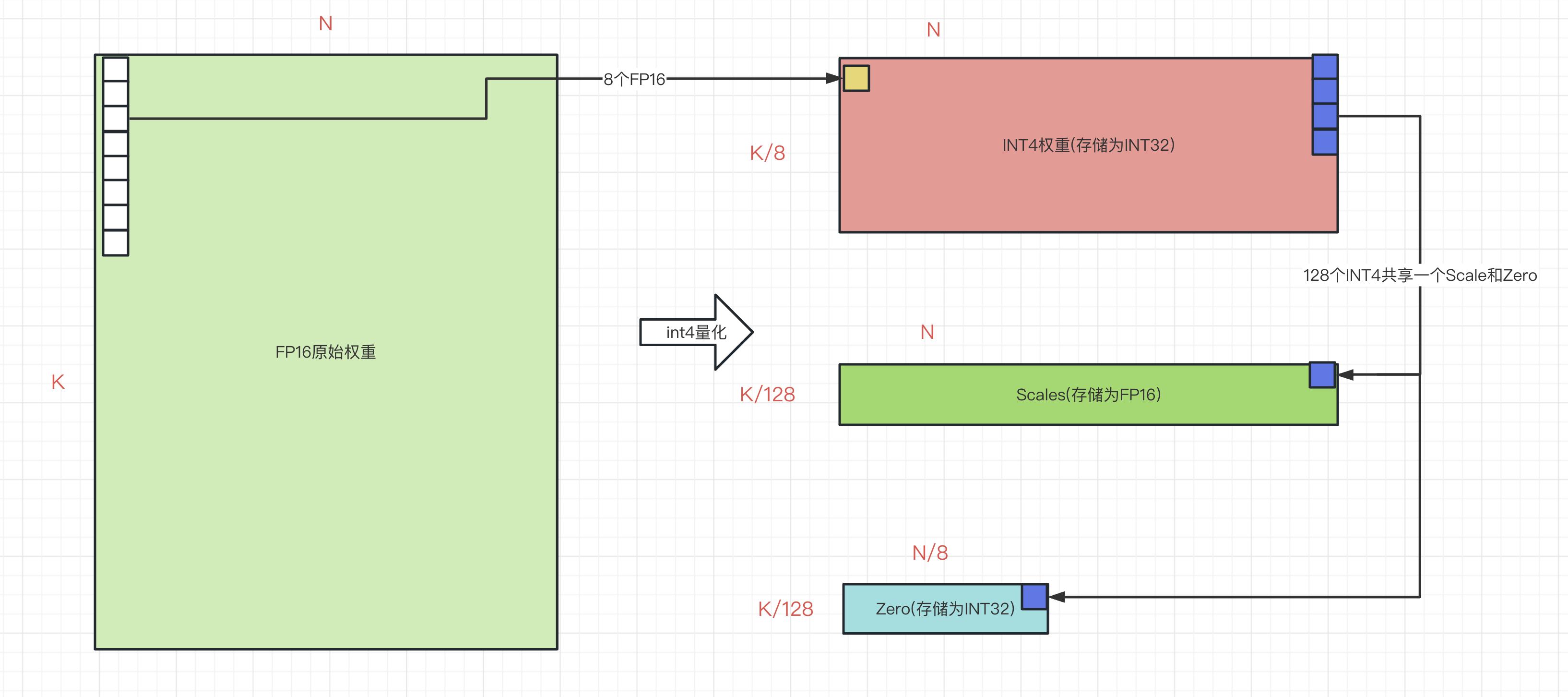
INT4权重说明:
- 一个Linear层的fp16权重,输出3个权重:int4的权重,scale系数,zero。
- 三个权重的类型和尺寸。假设原始fp16权重为[K, N], 则:
- int4_weight为[K/8, N] (一列的8个int4合并一个int32)
- scale为[K/128, N] (格式为fp16, 一列的128个权重共用一个scale, 128为量化时配置的groupsize)
- zero为[K/128, N/8] (一行8个int4合并一个int32, 一列的128个权重共用一个int4的zero)
转换脚本
修改huggingface_bloom_convert.py以支持转换int4权重,流程简单,关键代码:
|
|
模型加载
修改ParallelGptDecoderLayerWeight
替换矩阵乘kernel
封装vecquant4matmul_cuda算子成GptqGemmRunner类,然后替换掉
- self_attention.dense
- self_attention.query_key_value
- mlp.dense_4h_to_h
- mlp.dense_h_to_4h等处的调用, 示例:
|
|
二、kernel性能摸底
调通流程不难,难点在于kernel算子性能,未优化的int4 kernel性能不及FP16,不符合预期,性能优化势在必行。
1. 原始实现-old-cuda
- 功能:矩阵乘,假设C=A * B, A=[M, K], B=[K, N], C=[M, N]
- scalar_t为fp16, vec为A[M, K], mat为int4权重[K/8, N], mul为结果C[M, N], scales为[K/128, N], zeros为[K/128, N/8]
计算过程:
- 将mat切分为[BLOCKWIDTH, BLOCKWIDTH]的子矩阵,每个block处理[1, BLOCKWIDTH] * [BLOCKWIDTH, BLOCKWIDTH]的矩阵乘,子结果通过atomicAdd更新到mul中。
- K/BLOCKWIDTH个block的结果相加得到mul[1, BLOCKWIDTH]
- {K/BLOCKWIDTH, N/BLOCKWIDTH}个block处理[1, N]个结果
- {K/BLOCKWIDTH, N/BLOCKWIDTH, M}个block得到[M, N]个结果
- 每个线程处理BLOCKWIDTH个乘加
线程内的流程:
- BLOCKWIDTH个线程协作拷贝vec中BLOCKWIDTH个值到share memory中(变量blockvec)。
- 从mat中获取Int32的权重,通过scale和zero还原成8个fp16,与blockvec中的值进行乘加。
- 将乘加的结果通过atomicAdd保存到mul中。
kernel算子性能测试:
- 测试环境:A100单卡,权重为bloom 175B 2卡query_key_value的尺寸:14336*21504
- 矩阵乘算子耗时对比,时间单位(微秒)
| M | cublas FP16耗时 | int4算子-BLOCKWIDTH-256 | int4算子-BLOCKWIDTH-1024 |
|---|---|---|---|
| 1 | 372.794 | 419.525 | 271.103 |
| 2 | 373.715 | 1308.533 | 515.462 |
| 4 | 373.525 | 2544.975 | 958.13 |
| 8 | 378.458 | 5040.562 | 1905.114 |
| 16 | 384.483 | 10024.748 | 3815.136 |
| 128 | 395.75 | 79716.668 | 30248.278 |
| 256 | 704.908 | 159450.097 | 61029.231 |
| 320 | 967.704 | 199256.5 | 76277.884 |
结论:默认的实现有一些问题:
- int4比fp16约快37%(m=1),不符合预期,应该更快。因为带宽约降低75%,算力增加了约2倍,但带宽一般是瓶颈。
- 默认的BLOCKWIDTH配置的太小,计算访存比低,测试下来1024最优。
- 随着M的增加,耗时线性增加,原因是多个M未做还原复用。
2. half2实现fastest-inference-4bit
默认的kernel实现性能不理想,然后发现GPTQ-for-LLaMa项目里面针对int4进行了专项的优化.
优化思想:
- 向量化读取,将读取vec的过程改成half2的格式,加快读取的速度
- 乘加计算也通过half2的类型,减少算力占用
经过测试fastest-inference-4bit约提升18%,随着M的增加,耗时线性增加依旧。
三、kernel性能优化
因为性能依然不理想,所以基于fastest-inference-4bit进行优化,经过三轮优化,最终实现:
- 耗时降低到cublas fp16耗时的31% (m=1)
- 耗时降低到fastest-inference-4bit的51% (m=1)
- 初步解决了m增加,耗时线性增加到问题, m=16时耗时降低到fastest-inference-4bit的10%
看一下数据:
- 测试环境:A100单卡,权重为bloom 175B 2卡query_key_value的尺寸:14336*21504
- 矩阵乘算子耗时对比,时间单位(微秒)
- BLOCKWIDTH=1024
| m | cublas耗时 | int4-old-cuda-耗时 | int4-fastest-inference-4bit | 优化1 | 优化2 | 优化3 |
|---|---|---|---|---|---|---|
| 1 | 372.794 | 271.103 | 228.472 | 178.361 | 147.065 | 117.33 |
| 2 | 373.715 | 515.462 | 430.873 | 330.344 | 215.531 | 140.514 |
| 4 | 373.525 | 958.13 | 807.954 | 614.537 | 298.237 | 169.338 |
| 8 | 378.458 | 1905.114 | 1622.786 | 1202.168 | 386.775 | 266.117 |
| 16 | 384.483 | 3815.136 | 3266.978 | 2411.934 | 762.359 | 348.608 |
| 128 | 395.75 | 30248.278 | 26160.017 | 19724.196 | 6112.127 | 2639.796 |
| 256 | 704.908 | 61029.231 | 52545.124 | 39206.874 | 12224.146 | 5231.433 |
| 320 | 967.704 | 76277.884 | 65818.762 | 48847.196 | 18336.961 | 6698.273 |
讲一下3轮优化的思路:
优化1: scale和zero读取优化
优化思想:
- 合并减少读取scale和zero的次数 因为每128个权重共享一个scale和zero, 所以每128个int4权重读取一次scale和zero, 并不需要每8个int4读一次。
- 加大每个线程处理的结果数,每个线程处理2个结果。
优化效果:相比fastest-inference-4bit耗时降低22%。
优化2:解决m增加耗时增加问题
优化思想:
- 共享权重还原,多个m共享一次权重的读取和还原
- 减少bank冲突,加大deq2的冗余,减少冲突,当m=1,配置TBANK=32。
工程实现注意事项:
- 因为share memory的限制,最多16行vec共享一次权重读取和还原。m大于16时,16的整数倍通过配置blockIdx.z在一次kernel launch中执行,余数单独调用一次kernel launch
优化效果:相比fastest-inference-4bit耗时降低35%, 且m增加耗时增加问题较大改善。
优化3:提高带宽利用率
完成优化2后,用Nsight Compute分析瓶颈在mat读取。
优化思想:
- 合并读取,一个线程连续读取2个连续的int32。
- 向量化写入, 合并写入2个half为一个half2。
最终优化效果:
- 耗时降低到fastest-inference-4bit的51% (m=1)
- 初步解决了m增加,耗时线性增加到问题, m=16时耗时降低到fastest-inference-4bit的10%
最终矩阵乘代码:
|
|
优化4: 解决M>16后,耗时线性增长的问题
经过3轮优化后,m<16时,int4算子比cublas有明显优势,但当m>16时,int4算子耗时增加明显。
在FastTransformer中,有2个场景会用到m>16:
- 生成context阶段,即由embedding计算kv cache的时候,m=batch*input_token_len,m很容易超过16,一次推理调用一次,会影响首字耗时
- 生成一个token阶段,m=batch, 一般很难超过16
因为m>16会影响首字耗时,所以采用下列策略优化:
- 回退cublas,因为cublas对多m优化较好,所以实现了一个反量化的接口,对于m>48的场景先反量化到fp16,然后再调用cublas。48为实测下,反量化+cublas耗时小于int4算子耗时的拐点。
- 反量化需要显存,一块卡复用一个buf即可。
kernel优化的套路
因为我也是第一次做kernel优化,所以记录下:
- 规划好block和thread的职责,先实现一个简单的版本
- 核对kernel结果是否正确
- 调整grid和block的size, 对比测试找到一个最优的值
- 使用 Nsight Compute分析kernel的瓶颈, 需要关注的点:
- Occupancy,理论Occupancy和实际Occupancy
- Compute (SM) Throughput 和 Memory Throughput
- memory workload 里面的bank conflict
- Source Counters 可以定位warp挂起的原因
- 解决Nsight Compute分析出的瓶颈
- 常见的优化方法:多级存储,向量化读写
四、未完的事
- 继续优化int4的kernel, 在m>16后,应该有更优雅的实现方法
- 实现并验证双buf预取方法,增加带宽的利用率
- 一些疑点:为何INT2向量化读慢于2个int32
License 知识共享署名 3.0 中国大陆许可协议