大模型推理 - Prefix Caching加速
Contents
轻视
prefix caching是一个容易想到的大模型推理优化点,但VLLM&TGI推理框架都没有支持(截止2023年11月15日),只是在FasterTransfromer中隐约看到过,并不起眼的特性。现在想来这个方案之所以被轻视一是不容易写论文,二是业务上没有长的通用前缀,收益预期不大。
契机
直到我们有一个意图识别的业务上线后,请求的Latency很不稳定,有时1.5秒,有时6~7秒。经分析业务的请求属于长输入短输出:输入Token=1000, 输出Token=30,我们理论分析一下Latency:
Latency = 首字耗时500ms + 30 * PerTokenCost = 1550ms (设decode阶段PerTokenCost为35ms)
但真实的线上服务我们支持了Continuous batch,会将新的请求和老的请求拼在一起处理。因为输入Token=1K较长,batch对长token没有加速效果(1k=500ms, 2k=2*500ms),假如QPS=1的情况下,会发生如下图的情况:

- 每1秒会有一个新请求,其中耗时500ms处理首字
- 剩余的500ms生成了14个token,这样PerTokenCost变成了1000/14=70ms
- 套用前面公式:一次请求的
Latency = 500ms + 30 * 70 = 2600ms
可知长输入的首字耗时,侵占了decode的时间,随着QPS的增加,导致请求的整体耗时急剧增加。理论上QPS=2的时候,时间片会全部给首字,系统会超载,达到batch上限,最终无法接收新的请求。
再深入分析发现意图识别1000个输入token中有900个固定的前缀,这里prefix caching的收益就很可观了。结合经验分析prefix caching后首字耗时可以降低400ms,更重要的是减轻首字对decode的影响,会使多batch延迟更低更平稳。
实现
prefix caching的思想很简单,就是把特定前缀的kvcache缓存起来,但一涉及cuda算子和高性能又没有那么简单,有太多问题不可不察:
- context阶段的attention算子是否支持seq切分?
- 多个请求如何零拷贝复用prefix kv cache?
- 涉及位置编码相关算子是否要调整?
- 如何和continuous batch的调度结合?
- 如果保持接口兼容?
最终方案记录如下(需了解continuous batch的细节,见前文):
PrefixCacheManager
定义一个新的管理类,提供如下接口:
- add_prefix_prompt 添加一条前缀 prompt
- set_blocktable 给前缀项设置kvcache的页表
- is_requst_match_prefix 请求是否匹配前缀,匹配则返回blocktable
加载过程
- 通过配置文件加载前缀prompt(支持配置多条)
- 前缀经过tokenizer之后获取到token_ids, 调用add_prefix_prompt添加一条前缀
- 使用token_ids添加任务,调度器调度任务,kvcache自然的保存在CacheEngine中
- 拿到cache的页表信息blocktable调用set_blocktable保存。
调度过程
- 新的请求,调用is_requst_match_prefix接口,若匹配前缀,则获取到blocktable
- context阶段,调度器给batch打上prefix任务的标记,并传递prefix的blocktable信息。
假设总的输入prompt长度为total_seq_len, 其中匹配前缀为prefix_seq_len, 剩余为user_seq_len, 满足total_seq_len = prefix_seq_len + user_seq_len。
整个推理过程如图:
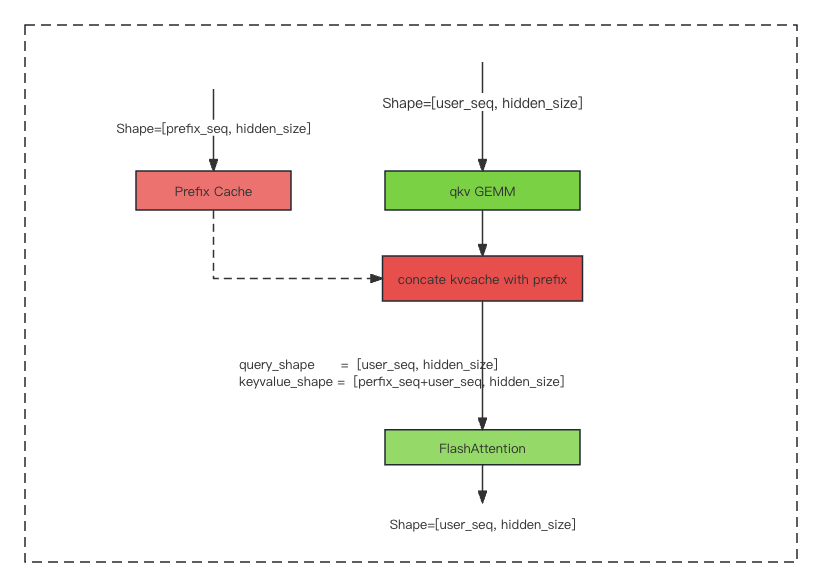
这里面有3个关键点:
- 担心FlashAttention算子在切分seq时有坑,万幸一切顺利。
- 要实现一个concate_kvcache_with_prefix算子,把prefix的cache和user_seq拼起来,因为cache是按PageAttention要求的格式存储,要了解FlashAttention和PageAttention输入cache格式的差异。
- 旋转位置编码的需要注意传入正确的total_seq_len。
- decode阶段,处理起来较简单,主要是将prefix的blocktable和user的blocktable拼起来,模型内部attention部分逻辑无需调整。这里面采取了一个取巧的方法,prefix_seq是页大小的整数倍,这样就没有任何的显存拷贝了,所有的请求可以复用同一块prefix cache显存。
提升
缓存的前缀长度约900, 经测试,优化后首字从500ms降低到100ms以内, 在Latency稳定在2秒以内的情况下,QPS从1提升到10+。(因某些原因,详细的测试数据不便披露)
展望
prefix针对特殊的业务是有效的,但另一些业务还是有随机的长prompt, 系统依然存在着速度不稳定的风险。对此英伟达的开发提出一个将context和decode分离的方案,目前看来是终极解决方案。
License 知识共享署名 3.0 中国大陆许可协议